Written by Sarthak Maji
Introduction
When the data of the star clusters are collected using a CCD camera, the data is saved as a FITS file. To handle this FITS file in python, first, we need to understand what FITS files are. FITS (Flexible Image Transport System) is a file format designed to store, transmit, and manipulate the data saved on the file. The data stored in a fits file is multi-dimensional, like a 2D array. The pixel data from the camera is stored as a 2D or 3D array depending on the type of image. For example, if the data is monochrome, it is stored as a 2D array; if it is RGB, it is stored as a 3D array. The image metadata is stored as headers in ASCII format, which is readable by humans.
Handling FITS file in Python
To handle the FITS file in python, we first need to install a package called AstroPy. AstroPy is installed using the command line function on our compiler, which is python. We also install other valuable packages like photutils which detect stars and their positions on the image.

In the command line, we use the pip command to install the latest version of AstroPy and other useful packages. Once the needed packages are installed, we must import all necessary packages onto the jupyter notebook. For example, to open the fits file, we need a specific function of astropy to handle fits; the fits function is imported from astropy.io, as shown in the code below.
import numpy as np
import matplotlib.pyplot as plt
from astropy.io import fits
from matplotlib.colors import LogNorm as log
from astropy.stats import SigmaClip
from photutils.background import Background2D, MedianBackground
Once the packages are imported, we import the fits file onto our jupyter notebook and save it to a variable, as shown in the code below. Every fits file is saved into different variables.
Img1 = ('M35_1306B.fit')
Img2 = ('M35_1307B.fit')
Img3 = ('M35_1308B.fit')
Img4 = ('M35_1309B.fit')
Img5 = ('M35_1310B.fit')
Img6 = ('M35_1311B.fit')
Img7 = ('M35_1312B.fit')
Img8 = ('M35_1313B.fit')
Img9 = ('M35_1314B.fit')
Img10 =('M35_1315B.fit')
Imgo = ('M35_1316Boff.fit')To ensure the fits files are imported correctly, we must also ensure that the fits files are saved in the same directory as the jupyter notebook. After importing the fits file onto a variable, as shown in the code above, we now need to open them to manipulate the data, which is done using the fits.open() function, as shown in the code below.
hdul1 = fits.open(Img1)
hdul2 = fits.open(Img2)
hdul3 = fits.open(Img3)
hdul4 = fits.open(Img4)
hdul5 = fits.open(Img5)
hdul6 = fits.open(Img6)
hdul7 = fits.open(Img7)
hdul8 = fits.open(Img8)
hdul9 = fits.open(Img9)
hdul10 = fits.open(Img10)
hdulo = fits.open(Imgo)Once the fits file is opened onto a variable, we now need to extract the data and store it onto another variable so that the data can be manipulated. The code to extract data is shown in the code below.
Data1 = hdul1[0].data.astype('int32')
Data2 = hdul2[0].data.astype('int32')
Data3 = hdul3[0].data.astype('int32')
Data4 = hdul4[0].data.astype('int32')
Data5 = hdul5[0].data.astype('int32')
Data6 = hdul6[0].data.astype('int32')
Data7 = hdul7[0].data.astype('int32')
Data8 = hdul8[0].data.astype('int32')
Data9 = hdul9[0].data.astype('int32')
Data10 = hdul10[0].data.astype('int32')
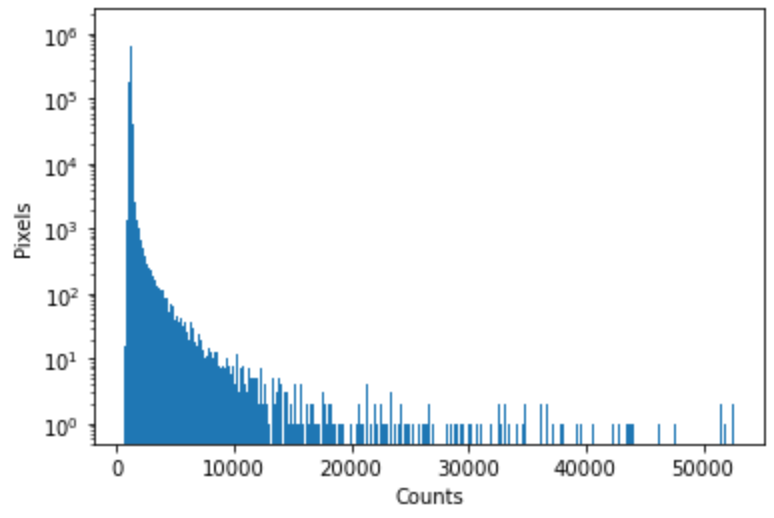
Datao = hdulo[0].data.astype('int32')We extract the data as a 32-bit file (as shown in the code above) so that while manipulating the data, we avoid problems like stack overflow while processing the images. The extracted data can remove hot pixels, background, and stacking. This extracted data is a 2D array where every data point is the pixel value. We can also determine the shape of the array, which gives us an idea of the no. of pixels in the camera sensor.
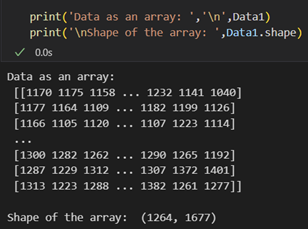

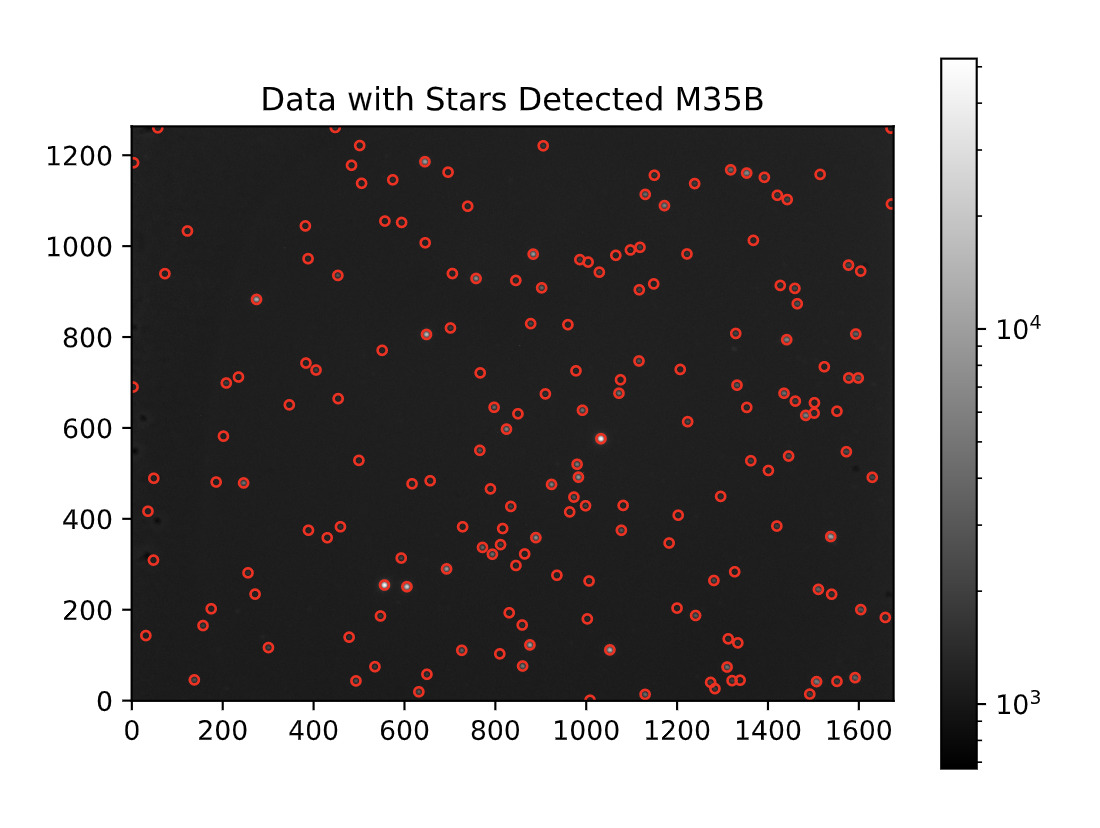
Figure 3 is the image representation of the extracted raw data of M35B in the log scale. This raw data contains hot pixels and a background, which is removed before stacking all the raw images collected.